|
SPSS: PROGRAMAS E ROTINAS COMPLEMENTARES (SYNTAX FILES) |
||
|
|
||
|
Proporções |
||
|
|
||
|
Teste para
uma proporção igual a um dado valor na
população |
||
|
Esta
sintaxe efectua o teste da diferença entre uma proporção observada
numa amostra e um dado valor da proporção na população, calculando,
igualmente, o intervalo de confiança e o poder observado. Para
além do número total da casos (N), da
proporção na amostra (P_A) e da
proporção na população (P_P), o utilizador
deve especificar o nível de confiança (NC),
para a determinação dos limites inferior (LIM_INF) e superior (LIM_SUP) do
intervalo de confiança, e o nível se significação (ALFA), a adoptar no cálculo do poder observado (PODER). A
sintaxe utiliza a aproximação normal (rigorosamente equivalente à
utilização do Teste do Qui-quadrado,
cf. Nota 1) à distribuição
binomial (cf. Nota 2), sendo o valor de zobs
corrigido para a continuidade (cf. Nota 3). O output divide-se em quatro partes: 1)
P_A (proporção na amostra, introduzida
pelo utilizador), P_P (proporção na
população, introduzida pelo utilizador – valores ente 0 e 1), N (total de casos na amostra, introduzido pelo
utilizador), Z (z observado) e
probabilidades bilateral (P_BI) e
unilateral (P_UNI); 2)
Z_C, P_BI_C
e P_UNI_C (valor de z corrigido para a
continuidade e respectivas probabilidade bilateral e unilateral; são estes os
valores a reter no teste de significação – cf. Nota 3); 3)
NC (nível de confiança, introduzido
pelo utilizador) e limites inferior (LIM_INF)
e superior (LIM_SUP) do intervalo de
confiança; 4)
ALFA (nível de significação para a
determinação do poder, introduzido pelo utilizador) e PODER (poder observado; cf. Cohen, 1988;
Borenstein, Rothstein & Cohen, 2001). Exemplo: Suponha que
pretende avaliar o método de tratamento do alcoolismo utilizado numa dada
clínica, sabendo que a taxa de sucesso na população em geral deste tipo de tratamentos
é de 34%. Obteve uma amostra aleatória de 160 pacientes dessa clínica, dos
quais 72 concluíram o tratamento com sucesso. Pode concluir que os resultados
dessa clínica estão acima da taxa de sucesso na população? |
||
|
*** Teste para uma proporção igual a um dado valor na população *** [Teste
z, Intervalo de Confiança e Poder
Observado] ***
Valentim Rodrigues Alferes (Universidade de Coimbra, 2003) *** NEW FILE. INPUT PROGRAM. END CASE. END END FILE. END INPUT PROGRAM. * Introduza a
proporção na amostra (no ex.: 72/160 = 0.45; cf. Nota 4). COMPUTE P_A = 0.45. * Introduza o N da
amostra. COMPUTE N = 160. * Introduza a
proporção na população (valor entre 0 e 1; no ex.: 0.34). COMPUTE P_P = 0.34. * Introduza o nível
de confiança (em percentagem) para a determinação * do intervalo de
confiança (por defeito, NC = 95). COMPUTE NC = 95. * Introduza o alfa
para o cálculo do poder (por defeito, ALFA = 0.05). COMPUTE ALFA = 0.05. COMPUTE Z=(P_A-P_P)/SQR(P_P*(1-P_P)/N). COMPUTE
P_BI=(1-CDFNORM(ABS(Z)))*2. COMPUTE
P_UNI=1-CDFNORM(ABS(Z)). COMPUTE
Z_C=(ABS(P_A-P_P)-(1/(2*N)))/SQR(P_P*(1-P_P)/N). COMPUTE
P_BI_C=(1-CDFNORM(ABS(Z_C)))*2. COMPUTE
P_UNI_C=1-CDFNORM(ABS(Z_C)). IF (Z<0) Z_C=-Z_C. COMPUTE Q=1-P_A. COMPUTE
Z_NC=IDF.NORMAL(NC/100+(1-NC/100)/2,0,1). COMPUTE A=Z_NC**2/N. COMPUTE LIM_INF=(P_A+A/2-Z_NC*SQR(((P_A*Q)/N)+(A/(4*N))))/(1+A). COMPUTE LIM_SUP=(P_A+A/2+Z_NC*SQR(((P_A*Q)/N)+(A/(4*N))))/(1+A). COMPUTE RQP1=SQR(P_A). COMPUTE H1=2*ARTAN(RQP1/SQR(-RQP1*RQP1+1)). COMPUTE RQP2=SQR(P_P). COMPUTE
H2=2*ARTAN(RQP2/SQR(-RQP2*RQP2+1)). COMPUTE HDIF=H1-H2. COMPUTE
Z_ALFA=IDF.NORMAL(1-ALFA/2,0,1). COMPUTE
ZPODER1=ABS(HDIF*SQR(2))*SQR(N/2)-Z_ALFA. COMPUTE
ZPODER2=-ABS(HDIF*SQR(2))*SQR(N/2)-Z_ALFA. COMPUTE
PODER1=CDF.NORMAL(ZPODER1,0,1). COMPUTE
PODER2=CDF.NORMAL(ZPODER2,0,1). COMPUTE
PODER=PODER1+PODER2. EXECUTE. FORMATS P_A(F8.4)
P_P(F8.4) N(F12.0) Z(F8.4) P_BI(F8.4) P_UNI(F8.4) NC(F8.0) LIM_INF(F8.4)
LIM_SUP(F8.4) ALFA(F8.4) PODER(F8.4) Z_C(F8.4) P_BI_C(F8.4)
P_UNI_C(F8.4). LIST P_A P_P N Z P_BI
P_UNI. LIST Z_C P_BI_C P_UNI_C. LIST NC LIM_INF LIM_SUP. LIST ALFA PODER. |
||
|
*** Teste para uma
proporção igual a um dado valor na população *** [Teste z,
Intervalo de Confiança e Poder Observado] *** Valentim
Rodrigues Alferes (Universidade de Coimbra, 2003) *** [...] LIST P_A P_P N Z P_BI
P_UNI. List P_A
P_P N Z
P_BI P_UNI ,4500
,3400 160 2,9373
,0033 ,0017 Number of cases
read: 1 Number of cases listed: 1 LIST Z_C P_BI_C P_UNI_C. List Z_C
P_BI_C P_UNI_C 2,8538
,0043 ,0022 Number of cases
read: 1 Number of cases listed: 1 LIST NC LIM_INF LIM_SUP. List NC
LIM_INF LIM_SUP 95
,3750 ,5274 Number of cases
read: 1 Number of cases listed: 1 LIST ALFA PODER. List ALFA
PODER ,0500 ,8141 Number
of cases read: 1 Number of cases listed: 1 |
||
|
A aproximação ao problema via Teste z é rigorosamente
idêntica à aproximação via Teste do
Qui-Quadrado, que pode obter através da sintaxe que se segue. Como se verifica no output, as respectivas
probabilidades são iguais (note que z2 = c2),
o mesmo se passando com os valores corrigidos para a continuidade. NEW FILE. INPUT PROGRAM. LOOP GRUPO=1 TO 2. END CASE. END END FILE. END INPUT PROGRAM. * Introduza a proporção na amostra (no ex.: 72/160 = 0.45; cf. Nota
4). COMPUTE P_A = 0.45. * Introduza o N da amostra. COMPUTE N = 160. * Introduza a proporção na população (valor entre 0 e 1; no ex.:
0.34). COMPUTE P_P = 0.34. COMPUTE FT=P_P*N. COMPUTE FO=RND(P_A*N). IF ($CASENUM=1) FREQ_OBS=FO. IF ($CASENUM=2) FREQ_OBS=N-FO. IF ($CASENUM=1) FREQ_TEO=FT. IF ($CASENUM=2) FREQ_TEO=N-FT. COMPUTE QUI=(FREQ_OBS-FREQ_TEO)**2/FREQ_TEO. COMPUTE QUI_C=((ABS(FREQ_OBS-FREQ_TEO)-.5)**2)/(FREQ_TEO). COMPUTE RESIDUOS=FREQ_OBS-FREQ_TEO. EXECUTE. FORMATS GRUPO FREQ_OBS(F8.0) FREQ_TEO RESIDUOS (F8.2). LIST GRUPO FREQ_OBS FREQ_TEO RESIDUOS. AGGREGATE/OUTFILE=*/BREAK=N/P_A=FIRST(P_A)/P_P=FIRST(P_P) /QUI=SUM(QUI)/QUI_C=SUM(QUI_C)/GL=FIRST(GRUPO). COMPUTE P_BI_C=1-CDF.CHISQ(QUI_C,GL). COMPUTE P_BI=1-CDF.CHISQ(QUI,GL). COMPUTE P_UNI_C=P_BI_C/2. COMPUTE P_UNI=P_BI/2. EXECUTE. FORMATS GL(F8.0) QUI P_BI P_UNI QUI_C P_BI_C P_UNI_C P_A P_P(F8.4). LIST P_A P_P QUI GL P_BI P_UNI. LIST QUI_C GL P_BI_C P_UNI_C. […] LIST
GRUPO FOBS FTEO RESIDUOS. List GRUPO
FOBS FTEO RESIDUOS 1
72 54,40 17,60 2
88 105,60 -17,60 Number
of cases read: 2 Number of cases listed: 2 […] LIST
P_A P_P QUI GL P_BI P_UNI. List P_A
P_P QUI GL
P_BI P_UNI ,4500
,3400 8,6275 1
,0033 ,0017 Number
of cases read: 1 Number of cases listed: 1 LIST
QUI_C GL P_BI_C P_UNI_C. List QUI_C
GL P_BI_C P_UNI_C 8,1442 1
,0043 ,0022 Number of cases read: 1
Number of cases listed: 1 |
||
|
Em rigor, o presente teste deve ser feito
através da distribuição binomial
que nos dá a probabalidade exacta.
Para isso, pode utilizar os menus do SPSS Data Editor (Analyze
/ Nomparametric Tests / Binomial... ) ou a seguinte sintaxe: NEW
FILE. INPUT
PROGRAM. END
CASE. END
END
FILE. END INPUT PROGRAM. * Introduza a proporção na amostra (no ex.: 72/160 = 0.45; cf. Nota 4). COMPUTE P_A = 0.45. * Introduza o N da amostra. COMPUTE N = 160. COMPUTE FX=RND(P_A*N). IF
($CASENUM=1) FREQ=FX. IF
($CASENUM=2) FREQ=N-FX. WEIGHT
BY FREQ. * Introduza a proporção na população (valor entre 0 e 1; no ex.:
0.34). NPAR TEST/BINOMIAL(.34)=X/METHOD=EXACT
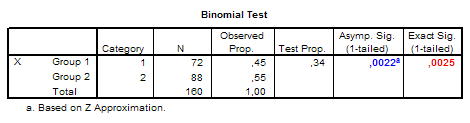
TIMER(5). Output
|
||
|
Note que a
probabilidade exacta fornecida no output
é a probabilidade unilateral, o que está em consonância com a natureza
direccional da hipótese do presente exemplo. Caso a hipótese seja não
direccional, deve multiplicar esta probabilidade por dois para obter a probabilidade
bilateral. |
||
|
Como se pode observar no no output
principal e nos output da Nota 1, tanto o Teste z
ou do Teste do Qui-Quadrado, com
ou sem correcção para a continuidade, conduzem à rejeição da hipótese nula,
i.e., corroboram a hipótese de que os resultados desta clínica são superiores
à taxa de sucesso na população em geral. De qualquer modo, deve reter a opção mais
rigorosa, ainda que mais conservadora, da correcção para a continuidade. Note
que neste exemplo, em que estamos perante uma hipótese direccional, as
probabilidade unilaterais corrigidas para a continuidade (p = 0.0022)
constituem, efectivamente, uma excelente aproximação à probabilidade exacta
dada pelo Teste Binomial (p =
0.0025, assinalada a vermelho no Output da Nota 2). Historicamente, o recurso ao Teste z ou ao Teste do Qui-Quadrado encontra
justificação na dificuldade em calcular as probabilidades exactas para
valores elevados de N. Como o SPSS
faz essa tarefa em poucos segundos, recomendamos
ao utilizador que indique sempre a probabilidade exacta dada pelo Teste
Binomial. Caso o N seja demasiado elevado pode obter a seguinte mensagem ao correr a
sintaxe da Nota 2: There is insufficient special working memory to
process all the cases. Break up the request, rerun with more workspace, or
use the SAMPLE subcommand. You can increase workspace with the SET WORKSPACE
command, or change the Special Working Memory Limit in the Preferences Dialog
Box. Siga estas instruções, por exemplo: SET WORKSPACE=15000. * O valor por defeito é de 512. ou, pura e simplemente, indique a probabilidade
do Teste z ou do Teste do Qui-Quadrado, que, nesta situação, não difere da
probabilidade exacta. |
||
|
Para evitar erros de arredondamento (o que não é
aqui o caso, uma vez que 72/160 é uma dízima finita), é preferível exprimir a
proporção na amostra sob a forma
de fracção. Por exemplo, nas três
sintaxes desta página, a linha: COMPUTE P_A = 0.45. seria substituída pela linha: COMPUTE P_A = 72/160. Se, por exemplo, num artigo publicado, o
autor nos diz que 36.4% dos 107 sujeitos responderam correctamente a um item,
é preferível calcular retrospectivamente os efectivos, arredondando o
resultado para o inteiro mais próximo: 0.364 x 107 = 38.948 @ 39 e escrever: COMPUTE P_A = 39/107. em vez de: COMPUTE P_A = 0.364. |
||
|
Referências |
||
|
Cohen,
J. (1988). Statistical power analysis
for the behavioral sciences (2nd ed.). Borenstein,
M., Rothstein, H., & Cohen, J. (2001). SamplePower 2.0 [Computer Manual]. |
||
|
|
||
|
Última actualização: 2003-04-09 |
||